一点点想法,关于Spark执行引擎大幅优化
纠错
29 Apr 2015
其中有三点性能优化的方法。
原文:Project Tungsten: Bringing Spark Closer to Bare Metal
Memory Management and Binary Processing: leveraging application semantics to manage memory explicitly and eliminate the overhead of JVM object model and garbage collection
Cache-aware computation: algorithms and data structures to exploit memory hierarchy
Code generation: using code generation to exploit modern compilers and CPUs
贴一下第一点的图。
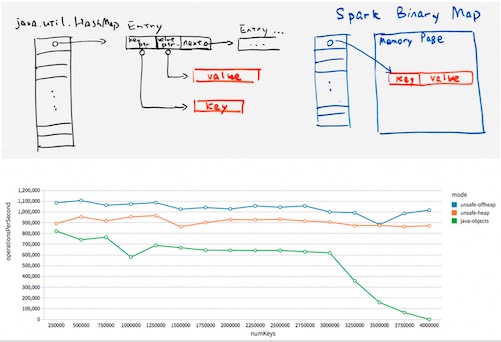
想了下Spark Binary Map,通过unsafe的确可以访问对象的内存地址,如果java中保存的是内存地址,查找如何做呢?
等待。。。。。。
上篇:
关于JVM的operand stack(操作数栈)
下篇:
通过JNI调用线程执行